
© 2013, NVIDIA CORPORATION. All rights reserved.
Code and text by Sean Baxter, NVIDIA Research.
(Click here for license. Click here for contact information.)
You can download a snapshot of the repository here.
Users may find more flexibility if they fork this repository. At https://github.com/NVlabs/moderngpu, click on the Fork button in the upper-right. This creates a copy of the repository in your own github account.
git clone git@github.com:yourname/moderngpu
From the command line you can clone your own fork of the project onto your local machine. You can make changes to the project and these will be updated in your own repository. Users forking MGPU are treated to Github's excellent suite of development tools. Use the Network Graph Visualizer to stay current with Modern GPU updates.
The Modern GPU library is entirely defined in headers under the include directory, except for one .cu and one .cpp files that must be compiled and linked manually: src/mgpucontext.cu and src/mgpuutil.cpp. This library has not been tested on sm_1x targets, which use a different compiler stack; therefore targeting these architectures has been disabled in the headers.
All device and host functions are included from include/moderngpu.cuh; this is all you need to include to access everything. Additionally, all functions and types are defined inside the mgpu namespace.
To compile from the command line (from the moderngpu/demo directory):
nvcc -arch=sm_20 -I ../include/ -o demo ../src/mgpucontext.cu ../src/mgpuutil.cpp demo.cu
To specifically target multiple device architectures (necessary if you are using LaunchBox to tune kernels), try something like this:
nvcc -gencode=arch=compute_20,code=\"sm_20,compute_20\" ^
-gencode=arch=compute_35,code=\"sm_35,compute_35\" -I ../include -o demo ^
../src/mgpucontext.cu ../src/mgpuutil.cpp demo.cuDevelopers on Linux can modify one of the provided GNU Make files.
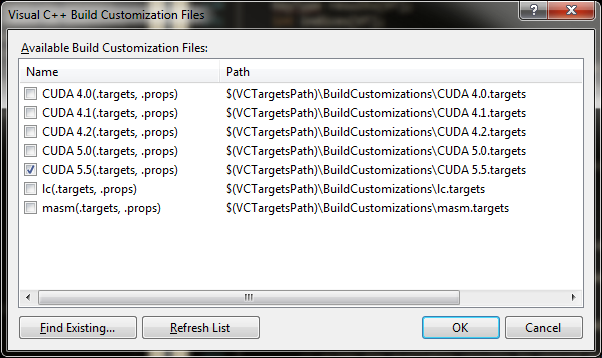
If you are a Visual Studio user, MGPU includes a solution for VS2010 with projects for the demo and each benchmark. To start a new project that uses CUDA and MGPU, create a new "Win32 Project" or "Win32 Console Project." Right-click on the project in the Solution Explorer and choose "Build Customizations..." This lists configuration files for each CUDA Toolkit installed on your system. Check the newest one:
Right-click on the project again, select "Add->Existing Items..." and add format.cpp, random.cpp, and mgpucontext.cpp from the src directory of your Modern GPU directory.
Optional: If you want to use the same project settings as MGPU, in the menu bar select "View->Property Manager." Right click on your project in the Property Manager and choose "Add Existing Property Sheet..." Select vs.props from the base directory of your MGPU install.
To configure CUDA properties for the project, go back to the Solution Explorer, right click on the project, and choose "Properties."
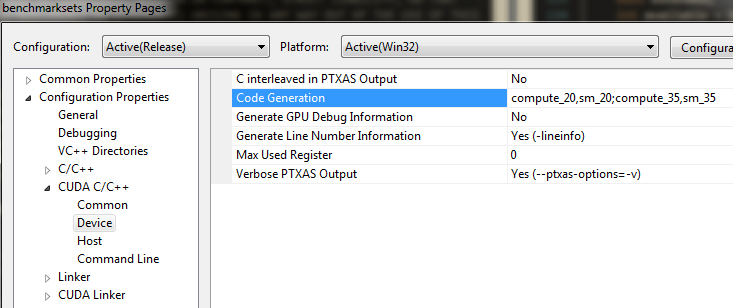
Make sure to compile with compute_20,sm_20 and higher; compute_1x will not build. You'll need to set mgpu/include under "Additional Include Directories" in the C/C++->General property page. Additionally you'll need to link against cudart.lib in Linker->Input->Additional Dependencies.
NVIDIA has offers Nsight, a rather impressive development and debugging suite for Visual Studio and Eclipse. I'm a bit of a luddite and mostly get by with two simple tools:
cuda-memcheck is a post-mortem debugger for the command line. When your kernel makes an out-of-range load/store or something else forbidden, cuda-memcheck aborts the program and prints detailed information on the nature of the error.
#include <cuda.h>
__global__ void Foo(int* data_global) {
__shared__ int s[128];
int tid = threadIdx.x;
s[tid + 1] = tid; // out-of-range store!
__syncthreads();
data_global[tid] = s[tid];
}
int main(int argc, char** argv) {
int* data;
cudaMalloc((void**)&data, 128 * sizeof(int));
Foo<<<1, 128>>>(data);
cudaDeviceSynchronize();
return 0;
}cuda-memcheck tests.exe ========= CUDA-MEMCHECK ========= Invalid __shared__ write of size 4 ========= at 0x00000020 in c:/projects/mgpulib/tests/test.cu:7:Foo(int*) ========= by thread (127,0,0) in block (0,0,0) ========= Address 0x00000200 is out of bounds ========= Saved host backtrace up to driver entry point at kernel launch time ========= Host Frame:C:\Windows\system32\nvcuda.dll (cuLaunchKernel + 0x166) [0xc196]
cuda-memcheck reports the nature of the error (invalid __shared__ write of size 4) and the function it occurred in. If you compile with -lineinfo (or select the appropriate box in the Visual Studio CUDA C/C++ properties), cuda-memcheck might even give you the line number, as it did in this case.
If you want more context, use cuobjdump to dump the disassembly of your kernel:
cuobjdump -sass tests.exe
Fatbin elf code:
================
arch = sm_20
code version = [1,6]
producer = cuda
host = windows
compile_size = 32bit
identifier = c:/projects/mgpulib/tests/test.cu
code for sm_20
Function : _Z3FooPi
/*0000*/ /*0x00005de428004404*/ MOV R1, c [0x1] [0x100];
/*0008*/ /*0x84001c042c000000*/ S2R R0, SR_Tid_X;
/*0010*/ /*0xfc1fdc03207e0000*/ IMAD.U32.U32 RZ, R1, RZ, RZ;
/*0018*/ /*0x08009c036000c000*/ SHL R2, R0, 0x2;
/*0020*/ /*0x10201c85c9000000*/ STS [R2+0x4], R0;
/*0028*/ /*0xffffdc0450ee0000*/ BAR.RED.POPC RZ, RZ;
/*0030*/ /*0x00201c85c1000000*/ LDS R0, [R2];
/*0038*/ /*0x80209c0348004000*/ IADD R2, R2, c [0x0] [0x20];
/*0040*/ /*0x00201c8590000000*/ ST [R2], R0;
/*0048*/ /*0x00001de780000000*/ EXIT;
.........................cuda-memcheck reported an "invalid __shared__ write of size 4" at address 0x00000020. The disassembly shows us the instruction at this address, and it is indeed an STS (store to shared 4 bytes).
Device-side printf is available on architectures sm_20 and later. It is extremely helpful. However you don't want 100,000 threads all printing to the console at once. Try to narrow down your problem to a single offending CTA and print from that. Individual printf statements are treated atomically (the entire string will come out at once), however the order in which threads print is undefined. It is helpful practice to store arguments to shared memory, synchronize, and have thread 0 read out the elements in order and printf in a loop.
The results of a device printf are not displayed until the next synchronizing runtime call after the kernel launch. This could be a cudaDeviceSynchronize, cudaMalloc, or cudaMemcpy.
Although printf is among the most primitive of debugging tools, it is surprisingly effective with data-parallel languages. Active debugging is often too fine-grained to understand the activity across an entire CTA.
How do I get started with CUDA?
The best place to get started with CUDA is the official Programming Guide. This is an up-to-date, correct, and concise overview of all of the device's capabilities and the APIs needed to use them.
There is a growing library of textbooks that paint a more detailed picture of GPU computing:
The CUDA Handbook - Nicholas Wilt
CUDA Programming - Shane Cook
CUDA Application Design and Development - Rob Farber
CUDA by Example - Jason Sanders
Programming Massively Parallel Processors - David Kirk and Wen-mei Hwu
Professor John Owens of UC Davis and Professor David Luebke, Graphics Research chief at NVIDIA, produced a video-rich CUDA course, available for free at Udacity, that covers hardware architecture, the CUDA toolkit, and parallel algorithms.
The CUDA Forums are the most trafficked pages for giving and receiving help. Stackoverflow also is very popular.
To contact me on email, use moderngpu@gmail.com.
Follow @moderngpu for notifications of new content.
I can often be found in #cuda on Freenode IRC.
The new Modern GPU library is provided under the 3-clause BSD license:
/****************************************************************************** * Copyright (c) 2013, NVIDIA CORPORATION. All rights reserved. * * Redistribution and use in source and binary forms, with or without * modification, are permitted provided that the following conditions are met: * * Redistributions of source code must retain the above copyright * notice, this list of conditions and the following disclaimer. * * Redistributions in binary form must reproduce the above copyright * notice, this list of conditions and the following disclaimer in the * documentation and/or other materials provided with the distribution. * * Neither the name of the NVIDIA CORPORATION nor the * names of its contributors may be used to endorse or promote products * derived from this software without specific prior written permission. * * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" * AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE * IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE * ARE DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY * DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES * (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; * LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND * ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT * (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS * SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. * ******************************************************************************/