
© 2013, NVIDIA CORPORATION. All rights reserved.
Code and text by Sean Baxter, NVIDIA Research.
(Click here for license. Click here for contact information.)
Schedule multiple variable-length fill, gather, scatter, or move operations. Partitioning is handled by load-balancing search. Small changes in problem logic enable different behaviors. These functions are coarse-grained counterparts to Bulk Remove and Bulk Insert.
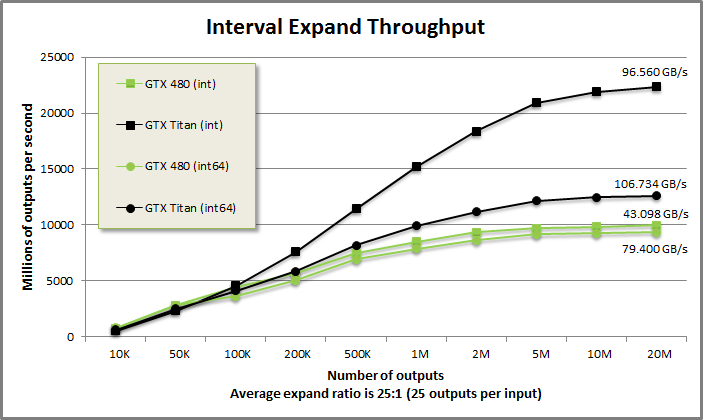
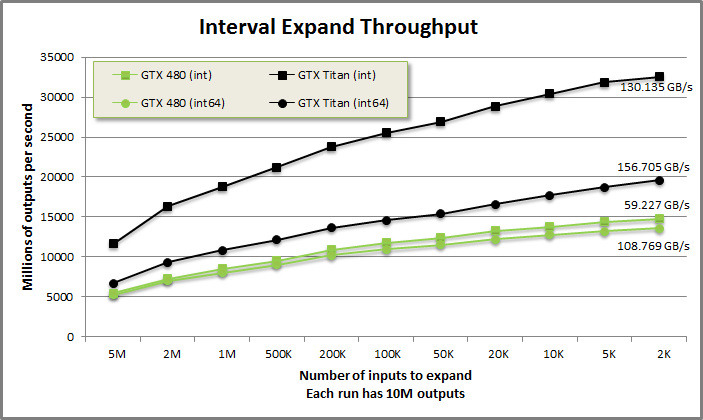
IntervalExpand benchmark from benchmarkintervalmove/benchmarkintervalmove.cu
Interval expand demonstration from tests/demo.cu
void DemoIntervalExpand(CudaContext& context) {
printf("\n\nINTERVAL-EXPAND DEMONSTRATION:\n\n");
const int NumInputs = 20;
const int Counts[NumInputs] = {
2, 5, 7, 16, 0, 1, 0, 0, 14, 10,
3, 14, 2, 1, 11, 2, 1, 0, 5, 6
};
const int Inputs[NumInputs] = {
1, 1, 2, 3, 5, 8, 13, 21, 34, 55,
89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765
};
printf("Expand counts:\n");
PrintArray(Counts, NumInputs, "%4d", 10);
printf("\nExpand values:\n");
PrintArray(Inputs, NumInputs, "%4d", 10);
MGPU_MEM(int) countsDevice = context.Malloc(Counts, NumInputs);
int total = Scan(countsDevice->get(), NumInputs, context);
MGPU_MEM(int) fillDevice = context.Malloc(Inputs, NumInputs);
MGPU_MEM(int) dataDevice = context.Malloc<int>(total);
IntervalExpand(total, countsDevice->get(), fillDevice->get(), NumInputs,
dataDevice->get(), context);
printf("\nExpanded data:\n");
PrintArray(*dataDevice, "%4d", 10);
}
INTERVAL-EXPAND DEMONSTRATION:
Expand counts:
0: 2 5 7 16 0 1 0 0 14 10
10: 3 14 2 1 11 2 1 0 5 6
Expand values:
0: 1 1 2 3 5 8 13 21 34 55
10: 89 144 233 377 610 987 1597 2584 4181 6765
Expanded data:
0: 1 1 1 1 1 1 1 2 2 2
10: 2 2 2 2 3 3 3 3 3 3
20: 3 3 3 3 3 3 3 3 3 3
30: 8 34 34 34 34 34 34 34 34 34
40: 34 34 34 34 34 55 55 55 55 55
50: 55 55 55 55 55 89 89 89 144 144
60: 144 144 144 144 144 144 144 144 144 144
70: 144 144 233 233 377 610 610 610 610 610
80: 610 610 610 610 610 610 987 987 1597 4181
90: 4181 4181 4181 4181 6765 6765 6765 6765 6765 6765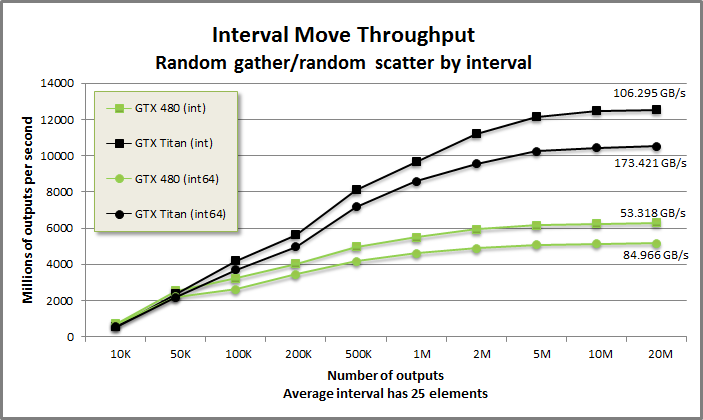
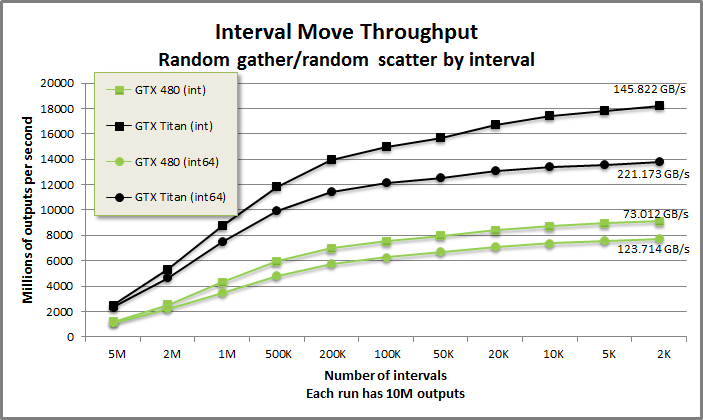
IntervalMove benchmark from benchmarkintervalmove/benchmarkintervalmove.cu
Interval move demonstration from tests/demo.cu
void DemoIntervalMove(CudaContext& context) {
printf("\n\nINTERVAL-MOVE DEMONSTRATION:\n\n");
const int NumInputs = 20;
const int Counts[NumInputs] = {
3, 9, 1, 9, 8, 5, 10, 2, 5, 2,
8, 6, 5, 2, 4, 0, 8, 2, 5, 6
};
const int Gather[NumInputs] = {
75, 86, 17, 2, 67, 24, 37, 11, 95, 35,
52, 18, 47, 0, 13, 75, 78, 60, 62, 29
};
const int Scatter[NumInputs] = {
10, 80, 99, 27, 41, 71, 15, 0, 36, 13,
89, 49, 66, 97, 76, 76, 2, 25, 61, 55
};
printf("Interval counts:\n");
PrintArray(Counts, NumInputs, "%4d", 10);
printf("\nInterval gather:\n");
PrintArray(Gather, NumInputs, "%4d", 10);
printf("\nInterval scatter:\n");
PrintArray(Scatter, NumInputs, "%4d", 10);
MGPU_MEM(int) countsDevice = context.Malloc(Counts, NumInputs);
MGPU_MEM(int) gatherDevice = context.Malloc(Gather, NumInputs);
MGPU_MEM(int) scatterDevice = context.Malloc(Scatter, NumInputs);
int total = Scan(countsDevice->get(), NumInputs, context);
MGPU_MEM(int) dataDevice = context.Malloc<int>(total);
IntervalMove(total, gatherDevice->get(), scatterDevice->get(),
countsDevice->get(), NumInputs, mgpu::counting_iterator<int>(0),
dataDevice->get(), context);
printf("\nMoved data:\n");
PrintArray(*dataDevice, "%4d", 10);
}
INTERVAL-MOVE DEMONSTRATION:
Interval counts:
0: 3 9 1 9 8 5 10 2 5 2
10: 8 6 5 2 4 0 8 2 5 6
Interval gather:
0: 75 86 17 2 67 24 37 11 95 35
10: 52 18 47 0 13 75 78 60 62 29
Interval scatter:
0: 10 80 99 27 41 71 15 0 36 13
10: 89 49 66 97 76 76 2 25 61 55
Moved data:
0: 11 12 78 79 80 81 82 83 84 85
10: 75 76 77 35 36 37 38 39 40 41
20: 42 43 44 45 46 60 61 2 3 4
30: 5 6 7 8 9 10 95 96 97 98
40: 99 67 68 69 70 71 72 73 74 18
50: 19 20 21 22 23 29 30 31 32 33
60: 34 62 63 64 65 66 47 48 49 50
70: 51 24 25 26 27 28 13 14 15 16
80: 86 87 88 89 90 91 92 93 94 52
90: 53 54 55 56 57 58 59 0 1 17//////////////////////////////////////////////////////////////////////////////// // kernels/intervalmove.cuh // IntervalExpand duplicates intervalCount items in values_global. // indices_global is an intervalCount-sized array filled with the scan of item // expand counts. moveCount is the total number of outputs (sum of expand // counts). // Eg: // values = 0, 1, 2, 3, 4, 5, 6, 7, 8 // counts = 1, 2, 1, 0, 4, 2, 3, 0, 2 // indices = 0, 1, 3, 4, 4, 8, 10, 13, 13 (moveCount = 15). // Expand values[i] by counts[i]: // output = 0, 1, 1, 2, 4, 4, 4, 4, 5, 5, 6, 6, 6, 8, 8 template<typename IndicesIt, typename ValuesIt, typename OutputIt> MGPU_HOST void IntervalExpand(int moveCount, IndicesIt indices_global, ValuesIt values_global, int intervalCount, OutputIt output_global, CudaContext& context); // IntervalMove is a load-balanced and vectorized device memcpy. // It copies intervalCount variable-length intervals from user-defined sources // to user-defined destinations. If destination intervals overlap, results are // undefined. // Eg: // Interval counts: // 0: 3 9 1 9 8 5 10 2 5 2 // 10: 8 6 5 2 4 0 8 2 5 6 // Scan of interval counts (indices_global): // 0: 0 3 12 13 22 30 35 45 47 52 // 10: 54 62 68 73 75 79 79 87 89 94 (moveCount = 100). // Interval gather (gather_global): // 0: 75 86 17 2 67 24 37 11 95 35 // 10: 52 18 47 0 13 75 78 60 62 29 // Interval scatter (scatter_global): // 0: 10 80 99 27 41 71 15 0 36 13 // 10: 89 49 66 97 76 76 2 25 61 55 // This vectorizes into 20 independent memcpy operations which are load-balanced // across CTAs: // move 0: (75, 78)->(10, 13) move 10: (52, 60)->(10, 18) // move 1: (86, 95)->(80, 89) move 11: (18, 24)->(49, 55) // move 2: (17, 18)->(99,100) move 12: (47, 52)->(66, 71) // move 3: ( 2, 11)->(27, 36) move 13: ( 0, 2)->(97, 99) // move 4: (67, 75)->(41, 49) move 14: (13, 17)->(76, 80) // move 5: (24, 29)->(71, 76) move 15: (75, 75)->(76, 76) // move 6: (37, 47)->(15, 25) move 16: (78, 86)->( 2, 10) // move 7: (11, 13)->( 0, 3) move 17: (60, 62)->(25, 27) // move 8: (95,100)->(36, 41) move 18: (62, 67)->(61, 66) // move 9: (35, 37)->(13, 15) move 19: (29, 35)->(55, 61) template<typename GatherIt, typename ScatterIt, typename IndicesIt, typename InputIt, typename OutputIt> MGPU_HOST void IntervalMove(int moveCount, GatherIt gather_global, ScatterIt scatter_global, IndicesIt indices_global, int intervalCount, InputIt input_global, OutputIt output_global, CudaContext& context); // IntervalGather is a specialization of IntervalMove that stores output data // sequentially into output_global. For the example above, IntervalGather treats // scatter_global the same as indices_global. template<typename GatherIt, typename IndicesIt, typename InputIt, typename OutputIt> MGPU_HOST void IntervalGather(int moveCount, GatherIt gather_global, IndicesIt indices_global, int intervalCount, InputIt input_global, OutputIt output_global, CudaContext& context); // IntervalScatter is a specialization of IntervalMove that loads input data // sequentially from input_global. For the example above, IntervalScatter treats // gather_global the same as indices_global. template<typename ScatterIt, typename IndicesIt, typename InputIt, typename OutputIt> MGPU_HOST void IntervalScatter(int moveCount, ScatterIt scatter_global, IndicesIt indices_global, int intervalCount, InputIt input_global, OutputIt output_global, CudaContext& context);
IntervalExpand was discussed in the introduction and we revisit it here, now with a solid understanding of the load-balancing search pattern at the implementation's heart.
include/kernels/intervalmove.cuh
template<typename Tuning, typename IndicesIt, typename ValuesIt,
typename OutputIt>
MGPU_LAUNCH_BOUNDS void KernelIntervalExpand(int destCount,
IndicesIt indices_global, ValuesIt values_global, int sourceCount,
const int* mp_global, OutputIt output_global) {
typedef MGPU_LAUNCH_PARAMS Tuning;
const int NT = Tuning::NT;
const int VT = Tuning::VT;
typedef typename std::iterator_traits<ValuesIt>::value_type T;
union Shared {
int indices[NT * (VT + 1)];
T values[NT * VT];
};
__shared__ Shared shared;
int tid = threadIdx.x;
int block = blockIdx.x;
// Compute the input and output intervals this CTA processes.
int4 range = CTALoadBalance<NT, VT>(destCount, indices_global, sourceCount,
block, tid, mp_global, shared.indices, true);
// The interval indices are in the left part of shared memory (moveCount).
// The scan of interval counts are in the right part (intervalCount).
destCount = range.y - range.x;
sourceCount = range.w - range.z;
// Copy the source indices into register.
int sources[VT];
DeviceSharedToReg<NT, VT>(NT * VT, shared.indices, tid, sources);
// Load the source fill values into shared memory. Each value is fetched
// only once to reduce latency and L2 traffic.
DeviceMemToMemLoop<NT>(sourceCount, values_global + range.z, tid,
shared.values);
// Gather the values from shared memory into register. This uses a shared
// memory broadcast - one instance of a value serves all the threads that
// comprise its fill operation.
T values[VT];
DeviceGather<NT, VT>(destCount, shared.values - range.z, sources, tid,
values, false);
// Store the values to global memory.
DeviceRegToGlobal<NT, VT>(destCount, values, tid, output_global + range.x);
}The load-balancing search maps output elements (range.x, range.y) and input elements (range.z, range.w) into each tile. All earlier routines process items in thread order—thread tid loads elements VT * tid + i (0 ≤ i < VT) from shared memory into register and processes them in register in an unrolled loop. This pattern is used to implement the load-balancing search called at the top of KernelIntervalExpand as boilerplate, but it's not used to implement the specific behavior of IntervalExpand.
The load-balancing search returns enough context in shared memory to allow the kernel to cooperatively process elements in strided order rather than the customary thread order—thread tid processes elements index = NT * i + tid, where index < destCount. The change from strided to thread order means we can use the device functions in device/loadstore.cuh to solve this problem.
After CTALoadBalance is run we cooperatively load source indices from shared memory into register. These indices identify the "generating objects" for each output; that is, the search locates the index of the fill value for each of the outputs.
Expand counts:
0: 2 5 7 16 0 1 0 0 14 10
10: 3 14 2 1 11 2 1 0 5 6
Scan of expand counts:
0: 0 2 7 14 30 30 31 31 31 45
10: 55 58 72 74 75 86 88 89 89 94
Load-balancing search:
0: 0 0 1 1 1 1 1 2 2 2
10: 2 2 2 2 3 3 3 3 3 3
20: 3 3 3 3 3 3 3 3 3 3
30: 5 8 8 8 8 8 8 8 8 8
40: 8 8 8 8 8 9 9 9 9 9
50: 9 9 9 9 9 10 10 10 11 11
60: 11 11 11 11 11 11 11 11 11 11
70: 11 11 12 12 13 14 14 14 14 14
80: 14 14 14 14 14 14 15 15 16 18
90: 18 18 18 18 19 19 19 19 19 19
Consider the example of IntervalExpand in demo.cu. We have 20 random expand counts that add up to 100. The client performs an exclusive scan over the counts and calls IntervalExpand. Our kernel runs CTALoadBalance to pair each of the 100 outputs with one of the 20 fill values. DeviceMemToMemLoop loads the interval of fill values (each associated with a "generating object") referenced by the tile into shared memory. Because the load-balancing search maps in a constant number of output plus input items to each tile, there's no risk of not having enough shared memory capacity in the CTA to accommodate this load: a run of thousands of 0 counts would result in a CTA that is mapped to a full-tile of source objects (NV + 1, keeping in mind the precedingB index) and no output objects. Although this may seem like an inefficiency, this division of source and destination items lets the kernel handle any distribution of expand counts without any special-case code.
Expand values:
0: 1 1 2 3 5 8 13 21 34 55
10: 89 144 233 377 610 987 1597 2584 4181 6765
Expanded data:
0: 1 1 1 1 1 1 1 2 2 2
10: 2 2 2 2 3 3 3 3 3 3
20: 3 3 3 3 3 3 3 3 3 3
30: 8 34 34 34 34 34 34 34 34 34
40: 34 34 34 34 34 55 55 55 55 55
50: 55 55 55 55 55 89 89 89 144 144
60: 144 144 144 144 144 144 144 144 144 144
70: 144 144 233 233 377 610 610 610 610 610
80: 610 610 610 610 610 610 987 987 1597 4181
90: 4181 4181 4181 4181 6765 6765 6765 6765 6765 6765The fill values, the first 20 numbers of the Fibonacci sequence, are cooperatively loaded into shared memory. DeviceGather cooperatively gathers the fill values for all destCount outputs using the source indices computed by CTALoadBalance and pulled from shared memory earlier. Because we process data in strided order rather than thread order, we can store directly to global memory without first having to transpose through shared memory: DeviceRegToGlobal cooperatively stores outputs to dest_global.
Important: The techniques illustrated on this page are about exposing parallelism in irregular problems. The naive approach for IntervalExpand would be to assign one thread to each source value: each thread reads its source value and copies it a variable-number of times to the output. This is a miserably unsatsifying solution, though. Huge penalties are taken due to control and memory divergence, the L2 cache is thrashed, and depending on the distribution of counts in the problem, there may not even be enough parallelism to even keep the device busy.
To address load imbalance, the developer could try to build heuristics that examine the expand counts and assign different widths of execution to each source value. Entire warps could be assigned to sources that fill more than 128 outputs, and whole CTAs to sources that fill more than 2048 elements, for example. But now we are innovating scheduling strategy rather than simply solving the interval expand problem. CTALoadBalance incurs only a modest cost to expose parallelism and nimbly load-balance any data distribution for this very common class of problems. Instead of thinking about scheduling you can focus on solving your problem.
IntervalMove is a vectorized cudaMemcpy. The caller enqueues transfers with (source offset, dest offset, item count) tuples. As with IntervalExpand, the counts are scanned prior to launch. The ability to load balance many cudaMemcpys over a single launch is crucial to performance—CUDA synchronizes at every cudaMemcpy, so calling that API directly will not deliver high throughput for many small requests. Host code may enqueue any number of transfers of any size and expect reasonable performance from IntervalMove.
IntervalMove and its special-case siblings—IntervalGather and IntervalScatter—are important primitives for GPU data structures. You can imagine "shaggy" binned data structures that resemble priority queues:
IntervalGather pulls items from the front bins.
IntervalScatter distributes sorted elements into the ends of all the bins.
IntervalMove, segmented sort, merge, and vectorized sorted search cooperate in joining and splitting bins to rebalance the data structure.
Operations could be scheduled on the CPU and executed en masse with MGPU's vectorized functions. It is hoped that the availability of these functions encourages users to experiment with parallel data structures, an area of computing that has gone almost totally unexamined.
include/kernels/intervalmove.cuh
template<typename Tuning, bool Gather, bool Scatter, typename GatherIt,
typename ScatterIt, typename IndicesIt, typename InputIt, typename OutputIt>
MGPU_LAUNCH_BOUNDS void KernelIntervalMove(int moveCount,
GatherIt gather_global, ScatterIt scatter_global, IndicesIt indices_global,
int intervalCount, InputIt input_global, const int* mp_global,
OutputIt output_global) {
typedef MGPU_LAUNCH_PARAMS Params;
const int NT = Params::NT;
const int VT = Params::VT;
__shared__ int indices_shared[NT * (VT + 1)];
int tid = threadIdx.x;
int block = blockIdx.x;
// Load balance the move IDs (counting_iterator) over the scan of the
// interval sizes.
int4 range = CTALoadBalance<NT, VT>(moveCount, indices_global,
intervalCount, block, tid, mp_global, indices_shared, true);
// The interval indices are in the left part of shared memory (moveCount).
// The scan of interval counts are in the right part (intervalCount).
moveCount = range.y - range.x;
intervalCount = range.w - range.z;
int* move_shared = indices_shared;
int* intervals_shared = indices_shared + moveCount;
int* intervals_shared2 = intervals_shared - range.z;
// Read out the interval indices and scan offsets.
int interval[VT], rank[VT];
#pragma unroll
for(int i = 0; i < VT; ++i) {
int index = NT * i + tid;
int gid = range.x + index;
interval[i] = range.z;
if(index < moveCount) {
interval[i] = move_shared[index];
rank[i] = gid - intervals_shared2[interval[i]];
}
}
__syncthreads();The IntervalMove host function runs an upper-bound MergePathPartitions in preparation for the load-balancing search. KernelIntervalMove calls CTALoadBalance which computes source indices into shared memory. The interval index (i.e. the index of the request that generated the output) and rank (of the element within the interval) are cooperatively pulled from shared memory in strided order. Recall that the rank is the difference between the output index and the exclusive scan of the generating object—both of these terms are returned by CTALoadBalance.
KernelIntervalMove (continued) from include/kernels/intervalmove.cuh
// Load and distribute the gather and scatter indices.
int gather[VT], scatter[VT];
if(Gather) {
// Load the gather pointers into intervals_shared.
DeviceMemToMemLoop<NT>(intervalCount, gather_global + range.z, tid,
intervals_shared);
// Make a second pass through shared memory. Grab the start indices of
// the interval for each item and add the scan into it for the gather
// index.
#pragma unroll
for(int i = 0; i < VT; ++i)
gather[i] = intervals_shared2[interval[i]] + rank[i];
__syncthreads();
}
if(Scatter) {
// Load the scatter pointers into intervals_shared.
DeviceMemToMemLoop<NT>(intervalCount, scatter_global + range.z, tid,
intervals_shared);
// Make a second pass through shared memory. Grab the start indices of
// the interval for each item and add the scan into it for the scatter
// index.
#pragma unroll
for(int i = 0; i < VT; ++i)
scatter[i] = intervals_shared2[interval[i]] + rank[i];
__syncthreads();
}
// Gather the data into register.
typedef typename std::iterator_traits<InputIt>::value_type T;
T data[VT];
if(Gather)
DeviceGather<NT, VT>(moveCount, input_global, gather, tid, data, false);
else
DeviceGlobalToReg<NT, VT>(moveCount, input_global + range.x, tid, data);
// Scatter the data into global.
if(Scatter)
DeviceScatter<NT, VT>(moveCount, data, tid, scatter, output_global,
false);
else
DeviceRegToGlobal<NT, VT>(moveCount, data, tid,
output_global + range.x);
}If gather indices are needed (for IntervalGather and IntervalMove), they are cooperatively loaded into shared memory. This is just one load per interval. After synchronization the gather indices (the source index for each copy request) are loaded from shared memory into register. We add the rank of the element into the gather index to produce a load index. For the i'th output, gather is the position to load the i'th input.
Scatter indices are treated symmetrically. If scatter indices are needed (for IntervalScatter and IntervalMove), they are cooperatively loaded into shared memory. This is just one load per interval. Scatter indices are loaded from shared memory into register. The rank is added to produce a store index. scatter is the position to store the i'th output.
As with IntervalExpand, the intra-CTA load-balancing search provides enough context so that each element can be processed independently. Rather than processing elements in thread order, where each thread processes elements VT * tid + i (0 ≤ i < VT), we cooperatively copy elements in strided order. The loadstore.cuh support functions complete the vectorized cudaMemcpys.